Um CAPTCHA usual envolve um computador (um servidor) que pede que um usuário termine um teste. Como os computadores são incapazes de resolver o CAPTCHA, todo usuário que incorpora uma solução correta é presumidamente humano. O termo foi inventado em 2000 por Luis von Ahn, por Manuel Blum, Nicholas J. Hopper (todos da universidade do Carnegie-Mellon), e por John Langford (da IBM).
Um tipo comum de CAPTCHA requer que o usuário identifique as letras de uma imagem distorcida, às vezes com a adição de uma sequência obscurecida das letras ou dos dígitos que apareça na tela.
Um CAPTCHA moderno. Ao invés de tentar criar um fundo distorcido e níveis elevados de distorção do texto, este CAPTCHA procura dificultar a segmentação adicionando uma linha angular
Atualmente, o reCAPTCHA é recomendado pelos criadores de CAPTCHA como a implementação oficial.
CAPTCHAs são utilizados para impedir que softwares automatizados executem ações que degradam a qualidade do serviço de um sistema dado, devido à despesa do abuso ou do recurso. Embora CAPTCHAs sejam utilizados mais frequentemente como uma resposta a proteção de interesses comerciais, a noção que existem para parar somente spammers é um erro, ou uma simples redução.
CAPTCHAs pode ser desdobrado para proteger os sistemas vulneráveis ao Spam de E-mail, tal como os serviços do AOL Webmail, do Gmail, do Hotmail, e do Yahoo. São também ativamente utilizados para limitar e controlar o acesso automatizado aos blogs ou os forums, em consequência de promoções comerciais, ou de vandalismo. CAPTCHAs servem também a uma função importante no controle da taxa limite, como o uso automatizado de um serviço pôde ser desejável até que tal uso esteja sendo realizado em excesso, e em detrimento de usuários humanos. Em tal caso, um CAPTCHA pode reforçar políticas automatizadas do uso como ajusta-se pelo administrador quando determinadas medidas do uso excedem um ponto inicial dado.
CAPTCHA é também o mecanismo sugerido para impedir listas automatizadas em placares e em votações de discussão pública. Um estudo por Arora e outros descreveu os vulnerabilidades nos vários fóruns públicos que não usam este tipo de teste (incluindo a BBC).
Um sistema de CAPTCHAs consiste em meios automatizados de gerar novos desafios que os computadores atuais são incapazes de resolver exatamente, mas a maioria de seres humanos podem resolver.[2] Um CAPTCHA não confia nunca no atacante que conheça previamente o desafio. Por exemplo, um checkbox "clique aqui se você é um bot" pode servir para distinguir entre seres humanos e computadores, mas não é um CAPTCHA porque confia no fato que um atacante não precisa se esforçar para quebrar esse formulário específico. Para ser um CAPTCHA, um sistema deve gerar automaticamente os novos desafios que requerem técnicas da inteligência artificial na resolução.
Na prática, o algoritmo usado para criar o CAPTCHA não necessita ser público, mas pode ser coberto por uma patente. Embora a publicação possa ajudar a demonstrar que a resolução requer a solução a um problema difícil no campo da inteligência artificial, reter deliberadamente o algoritmo pode aumentar a integridade de um jogo limitado dos sistemas (ver a segurança por meio do obscurecimento). O fator mais importante em decidir se um algoritmo deve ser feito aberto ou restrito é o tamanho do sistema. Embora um algoritmo que sobrevivesse a investida por peritos de segurança pudesse ser escolhido por ser conceitualmente mais seguro do que o algoritmo não validado, por outro lado apostar em um algoritmo desconhecido é sempre menos interessante àqueles que apostam no abuso automatizado. Quebrar um CAPTCHA requer geralmente algum esforço específico àquele implementação em particular, e um abusador pode decidir-se que o benefício concedido pelo desvio automatizado é inviável pelo esforço requerido para engajar no abuso desse sistema em primeiro lugar.
A primeira discussão acerca dos testes automatizados que distinguem seres humanos dos computadores com objetivo de controlar o acesso aos serviços da web aparece em um manuscrito 1996 de Moni Naor do instituto de Weizmann de ciência, intitulado "Verification of a human in the loop, or Identification via the Turing Test" (verificação de um ser humano no laço, ou identificação através do teste de Turing).
CAPTCHAs primitivos parecem ter sido desenvolvido mais tarde, em 1997, para o site de procura AltaVista por Andrei Broder e seus colegas para impedir que os bots adicionassem URLs a sua Ferramenta de Busca. Procurando uma maneira fazer suas imagens resistentes ao ataque do OCR, Optical Character Recognition (Reconhecimento Óptico de Caracteres), a equipe olhou o manual de scanner, obtendo recomendações para melhorar os resultados do OCR (typefaces similares, fundos lisos, etc.). A equipe criou enigmas tentando simular o que o manual reivindicado causaria a OCR mau. Em 2000, von Ahn e Blum desenvolveram e publicaram a noção de um CAPTCHA, que incluísse todo o programa que puder distinguir seres humanos dos computadores. Inventaram exemplos múltiplos, incluindo o primeiro CAPTCHAs a ser usado extensamente no Yahoo.
CAPTCHAs baseados em leitura de texto - ou outras tarefas de percepção visual - impedem que um usuário cego ou com restrições na visão acesse o recurso protegido. Cria também barreiras para um número grande de pessoas com as inabilidades de aprendizagem que envolvem a interpretação de texto. As falhas de projeto em alguns CAPTCHAs impedem mesmo a acessibilidade para usuários sem qualquer impedimento, por exemplo usando um zero (0) e (o). Para resolver corretamente um CAPTCHA, o usuário é requerido geralmente reconhecer todos os itens do CAPTCHA. Uma falha resulta que o usuário deva responder a um desafio novo.
Por ser projetado para ser ilegível às máquinas, as ferramentas de assistência comuns da tecnologia tais como leitores da tela não podem interpretá-los. Um CAPTCHA visual impede o acesso por usuários cegos, e pode impedir pessoas daltônicas. Para esta razão, algumas implementações permitem aos usuários optarem por um CAPTCHA de audio.[3] Mesmo com uma combinação de desafios do visual e do áudio, alguns usuários serão incapazes de usar um CAPTCHA, por exemplo usuários surdo-mudos.
A escolha de adicionar um CAPTCHA a uma aplicação é um contrapeso entre a facilidade de utilização para usuários legitimos e criar desafios para abusadores. A inconveniência causada por um CAPTCHA é às vezes mais elevada para usuários com inabilidades. Para algumas aplicações, o potencial para o abuso é de tal forma elevada que o autor da aplicação sente que um CAPTCHA é necessário. Para outras aplicações, a necessidade de acessibilidade compensa o abuso que impediria.
Houve várias tentativas em criar CAPTCHAs mais acessíveis. As tentativas incluem o uso do Javascript,[4] de perguntas matemáticas ("o que é 1+1"), ou "de perguntas do sentido comum" ("que cor é o céu"). Estas tentativas violam um ou ambos os princípios de CAPTCHAs: ou não podem automaticamente ser gerados ou podem facilmente ser resolvidos dada o estado da inteligência artificial. Como está, a única segurança fornecida pelo CAPTCHA é segurança por meio do obscurecimento; um atacante é improvável encontrar a formulação do CAPTCHA na pergunta, e improvável encontrá-la pelos recursos, da despesa e do tempo para quebrar o CAPTCHA mesmo de um site pequeno.
Há algumas aproximações em derrotar CAPTCHAs: usando o trabalho humano para reconhecê-los, explorando erros na implementação que permitam ao atacante contornar completamente o CAPTCHA, e finalmente em improvisar um software de reconhecimento de caractere.
CAPTCHA é vulnerável a um ataque que use seres humanos na resolução dos enigmas. De acordo com uma estimativa, os operadores poderiam facilmente resolver centenas delas cada hora. Se os seres humanos forem empregados dedicados que recebem salário mínimo isto não pode ser considerado viável,[5] mas os serviços como o Amazon Mechanical Turk tiveram o sucesso usando pagamento de pequeno vulto para atrair humanos na solução de outras tarefas. Uma outra variação desta técnica envolve copiar as imagens de CAPTCHA e usá-las como CAPTCHAs para um local do elevado-tráfego possuído pelo atacante. Com bastante tráfego, o atacante pode conseguir uma solução ao enigma do CAPTCHA.
As falhas de projeto em um CAPTCHA podem permitir burlar uma medida de segurança, ou poderiam tornar um ataque OCR mais fácil de montar.
Os sistemas de proteção de alguns CAPTCHAs podem ser contorneados sem usar o OCR simplesmente reutilizando a identificação de uma imagem conhecida do CAPTCHA. Corretamente projetado, um CAPTCHA não permite tentativas múltiplas da solução.[7] Isto impede reutilização de uma solução correta ou de fazer uma segunda suposição depois de uma tentativa incorreta do OCR.
Usar um sistema de criptografia muito simples e com poucas combinações.
Usando somente um pool fixo pequeno de imagens. Eventualmente, quando bastante soluções de imagem forem coletadas por um atacante sobre um período de tempo, o CAPTCHA pode ser quebrado simplesmente olhando acima das soluções em uma tabela, baseada em uma mistura da imagem do desafio.
Embora CAPTCHAs visuais sejam projetados originalmente para derrotar o software padrão do OCR projetado para a exploração do original, um número de projetos de pesquisa provaram que é possível derrotar muitos CAPTCHAs com programas que são ajustados especificamente para um tipo particular. Para CAPTCHAs com letras distorcidas, a aproximação consiste tipicamente nas seguintes etapas:
Extração da imagem da Web page.
Remoção da desordem do fundo, por exemplo com filtros da cor e detecção de linhas finas.
Segmentação, isto é rachando a imagem nos segmentos que contêm uma única letra.
Identificando a letra para cada segmento.
A maioria dos CAPTCHAs presentes na web trabalham como uma única linha de imagem. Algumas execuções racham a imagem nas peças múltiplas ou codificam as partes da imagem no código do HTML, forçando um processo automático para ler e executar o OCR na página.
A remoção da desordem é tipicamente muito fácil de fazer automaticamente. Em 2005, mostrou-se também que os algoritmos da rede neural têm uma taxa de erro mais baixa do que seres humanos na identificação do glyph.[8] A única parte onde os seres humanos ganham ainda dos computadores é segmentação. Se a desordem do fundo consistir em formas similares, e as letras estiverem conectadas por esta desordem, a segmentação torna-se quase impossível com software atual. Conclui-se que um CAPTCHA eficaz deve focalizar na segmentação.
Com a demonstração (através das publicações da pesquisa) que alguns CAPTCHAs são vulneráveis a reconhecedores de caracter e ataques, alguns estudiosos propuseram as alternativas ao reconhecimento de caráter, no formulário de reconhecimento CAPTCHA os usuários identificariam objetos simples nas imagens apresentadas. O argumento é que o reconhecimento do objeto está considerado tipicamente um problema mais complexo do que o reconhecimento de caracter, devido ao domínio limitado dos caracteres e dos dígitos nos alfabetos da maioria de línguas naturais.
Alguns dos inventores originais do sistema de CAPTCHA implementaram meios para medir e utilizar o esforço e tempo gasto pelas pessoas que estão respondendo aos desafios de CAPTCHA. Contando trabalho com elementos resolvidos" e "não resolvidos" incluindo imagens que não foram reconhecidos com sucesso através do OCR em cada desafio. Os mantedores do CAPTCHA estimam que os sistemas existentes de CAPTCHA representam aproximadamente 150.000 horas de trabalho por dia que poderia transparente ser batido através da revisão dos sistemas. Isto é aproximadamente 75 anos de trabalho diário realizado.
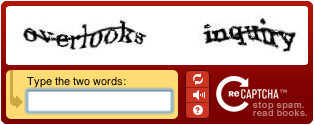
O ReCAPTCHA, projeto continuado do CAPTCHA utiliza como teste trechos não reconhecidos por OCRs em livros digitalizados. As respostas dos usuários, deste modo, serão utilizados na digitalização de conteúdo para web.
O serviço reCAPTCHA é um sistema de caixa de diálogo para usuário originalmente desenvolvido na Universidade Carnegie Mellon, principal campus de Pittsburgh. É baseado na interface do CAPTCHA, que pede para usuários digitarem palavras distorcidas exibidas na tela, para ajudar a digitalizar o texto de livros, enquanto protege sites de robôs tentando acessar áreas restritas.[1] Em 16 de Setembro de 2009, o Google adquiriu o reCAPTCHA.[2] Atualmente o reCAPTCHA está digitalizando os arquivos do New York Times e livros do Google Books. Desde 2009, vinte anos do New York Times já foi digitalizado e o planejamento do projeto seria completar o restante dos anos no final de 2010.[3]
O serviço reCAPTCHA fornece para sites inscritos, imagens de palavras que o reconhecimento óptico de caractéres (OCR) software não foi capaz de identificar. Os sites inscritos (os quais seus propósitos não são geralmente relacionados à ajuda do projeto de digitalização de livros) apresenta essas imagens para humanos decifrar como palavras CAPTCHAs, como parte do seu procedimento normal de validação. Depois eles retornam os resultados para o serviço reCAPTCHA, que envia esses resultados para a digitalização de seus projetos.
O sistema divulgou a mostra de mais de 100 milhões de CAPTCHAs todo dia[4], e tem alguns sites populares inscritos como Facebook, TicketMaster, Twitter, 4chan, CNN.com e StumbleUpon. O Craiglist começou a utilizar o serviço em Junho de 2008.[5] A Administração nacional de telecomunicações e informação dos Estados Unidos também usou o reCAPTCHA para o coupon de conversão de TV digital em seu site, como parte do plano de transição de TV digital dos EUA.
O programa reCAPTCHA originou-se com o cientista da computação Guatemalteco Luis von Ahn,[7] auxiliado pela Sociedade MacArthur. Um desenvolvedor de CAPTCHA precoce, ele percebeu que involuntariamente criou um sistema que estava desperdiçando, em incrementos de dez segundos, milhões de horas do mais precioso recurso: os ciclos do cérebro humano.
Textos escaneados são submetidos a dois diferentes tipos de programas de reconhecimento óptico de caractéres (OCR). Suas respectivas saídas são posteriormente alinhadas uma com a outra por um algoritmo de correspondência de cadeia e comparados um com o outro e com um dicionário inglês. Qualquer palavra que for decifrada diferentemente em ambos os programas de reconhecimento OCR ou que não está no dicionário inglês é marcada como "suspeita" e convertida em um CAPTCHA. A palavra suspeita é mostrada, fora de contexto, juntamente com uma palavra de controle que é conhecida. O sistema assume que se o usuário digitar a palavra de controle corretamente, então a resposta para a palavra questionada é aceita como provavelmente válida. Se usuários suficientes foram corretos em digitar a palavra de controle, mas digitar incorretamente a segunda palavra que o OCR falou em reconhecer, então a versão digital do documento poderá conter a palavra incorreta. Entretanto, devido ao erro humano em distinguir entre a palavra "Internet" e o nome francês "Infernet", referências para Captain infernet se tornaram ocasionalmente Captain internet.[9] A identificação praticada por cada programa OCR dá um valor de 0,5 pontos, e cada interpretação por um humano é dado um ponto completo. Uma vez que a identificação atinge 2,5 pontos, a palavra é considerada reconhecida. Aquelas palavras que são frequentemente dadas uma identificação única por julgadores humanos são depois recicladas como palavras de controle.[10]
O método original do reCAPTCHA foi concebido para mostrar as palavras questionáveis separadamente, como uma correção fora de contexto[11], em vez de em uso, como uma frase contendo 5 palavras do documento original. Também, a palavra de controle pode induzir ao erro o contexto para a segunda palavra, como um pedido de "/metal/ /fife/" sendo enviado como "metal file" devido a conexão lógica de apresentação com uma ferramenta de metal que estaria sendo considerada mais comum do que o instrumento musical fife (flauta).
Os testes do reCAPTCHA são exibidos do site central do projeto reCAPTCHA, o qual fornece as palavras a serem decifradas. Isto é feito através de uma API em JavaScript com o servidor fazendo uma chamada de volta para o reCAPTCHA após que o pedido foi submetido. O projeto reCAPTCHA provê bibliotecas para várias linguagens de programação e aplicações para tornar este processo mais fácil. reCAPTCHA é um serviço gratuito (isto é, as imagens CAPTCHA são providenciadas para os sites livre de cobranças, em troca pela assistência com o deciframento),[12] mas o software próprio do reCAPTCHA não é de código aberto.
Também, reCAPTCHA oferece plugins para várias aplicações na plataforma web, como ASP.NET, Ruby ou PHP, para facilitar a implementação deste serviço.
A base do sistema CAPTCHA é para prevenir acesso automático a um sistema por programas de computadores ou "bots" (robõs). Em 14 de Dezembro de 2009, Jonathan Wilkins divulgou um folheto descrevendo fraquezas no reCAPTCHA que permitiu resolver uma média de 18%.[13][14][15]
Em 1 de Agosto de 2010, Chad Houck deu uma apresentação para o DEF CON 18 Hacking Conference detalhando um método que reverte a distorção adicionada as imagens que permitiam um programa de computador determinar uma resposta válida 10% do tempo.[16][17] O sistema reCAPTCHA foi modificado em 21 de Julho de 2010, antes de Houck falar sobre seu método. Houck modificou o seu método para o que ele descreveu como um CAPTCHA mais fácil para determinar uma resposta válida 31,8% do tempo. Houck também mencionou defesas de segurança no sistema como uma trava de alta segurança se uma resposta válida não for dada em 32 vezes.[18]
Em 26 de Maio de 2012, Adam, C-P e Jeffball do DC949 deram uma apresentação no LayerOne Hacker Conference detalhando como eles foram capazes de criar uma solução automática com eficácia de 99,1%.[19] Sua tática consiste em usar uma forma de inteligência artificial conhecida como máquina de aprendizagem para analisar a versão de áudio do reCAPTCHA que está disponível para cegos e pessoas de baixa visão. O Google disponibilizou uma nova versão do reCAPTCHA apenas horas após a fala deles, e assim adicionou mudanças significativas em ambas as versões de áudio e visual do seu serviço. Nesta atualização, a versão de áudio foi aumentada de 8 segundos para 30 segundos, e é muito mais difícil agora de entender, tanto para humanos quanto robôs.
reCAPTCHA também criou um projeto chamado Mailhide (ocultação de email), que protege endereços de email em páginas da internet de serem capturadas por spammers[20]. Por padrão, o email é convertido em um formato que não permite ao capturador de ver o endereço completo do email. Por exemplo, "mailme@example.com" seria convertido em "mai...@example.com". O visitante teria que clicar no "..." e resolver um CAPTCHA para obter o endereço completo do email. Também é possível editar o código popup, então nada do endereço fica visível.
Nenhum comentário:
Postar um comentário